Monitoraggio con SNMP: Risoluzione dei problemi in God Mode
 il 14 lug 2020
il 14 lug 2020
Il monitoraggio della rete con SNMP non sempre funziona senza problemi. Ciò è spesso dovuto al fatto che molti produttori implementano il protocollo SNMP in modo piuttosto scadente nei loro dispositivi. Nell'ultimo articolo abbiamo già sottolineato i problemi che questo può causare al monitoraggio. Possibili segnali di problemi possono essere: il servizio Check_MK ha lo stato CRIT, si verifica un timeout durante l'inventario o i servizi Checkmk che dovrebbero essere presenti non vengono rilevati.
In questo articolo esamineremo la risoluzione dei problemi tipici di SNMP, nella cosiddetta "modalità Dio". Tuttavia, ciò significa anche che è necessario prestare particolare attenzione: da un grande potere derivano grandi responsabilità. Se implementato in modo errato, questo non risolverà il problema, ma potrebbe addirittura portare a un arresto completo del monitoraggio o causare pericolosi bug nei dispositivi che si desidera monitorare. In questo articolo daremo per scontato che avete già una buona conoscenza di Checkmk, quindi non spiegheremo qui la funzione del comando cmk. Una spiegazione dettagliata si trova nella documentazione.
Importante: Durante il debug, bisogna limitare sempre le impostazioni e i comandi al solo dispositivo interessato. Tutte le regole e le configurazioni elencate di seguito devono essere applicate SOLO agli host interessati e con attenzione.
L'articolo è strutturato come segue:
- Nozioni di base sul debug: il comando "cmk".
- Nozioni di base per il debug: SNMP inline rispetto a net-snmp
- Richieste bulk: Questione di scala
- Il tempismo è tutto
- Disattivare SNMP inline come soluzione
- Conclusione
Nozioni di base per il debug: il comando "cmk"
Partiamo dal presupposto che il comando cmk vi sia familiare. La combinazione con il comando Unix ‘time‘ è ottima per la risoluzione dei problemi. Utilizzeremo questa combinazione per rilevare vari problemi di runtime. Ad esempio, possiamo usare il comando time cmk -Iv HOSTNAME per determinare il tempo di esecuzione totale della fase di scoperta di un host:
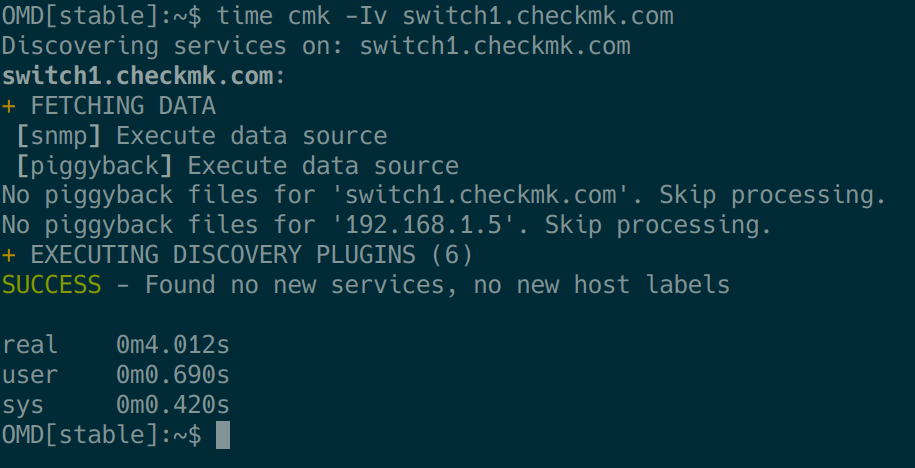
Allo stesso modo, è possibile utilizzare time cmk -nv HOSTNAME per verificare il tempo di esecuzione dell'interrogazione dei servizi rilevati.
È possibile inoltre ottenere informazioni ancora più dettagliate utilizzando due 'v', ad esempio cmk -Ivv HOSTNAME o cmk -nvv HOSTNAME. In questo modo si possono, tra l'altro, visualizzare gli OID che sono stati appena interrogati e quindi, ad esempio, identificare gli intervalli di OID lenti che potrebbero causare timeout.

Il tempo di esecuzione totale misurato in questo modo per la query (-n) o la discovery (-I/II) dovrebbe essere ben al di sotto dei 60 secondi per diversi motivi. Dopo tutto, il timeout standard del servizio "Check_MK" è di 60 secondi e dovrebbe quindi essere aumentato, insieme a un intervallo di controllo adeguato per le richieste di lunga durata. Un altro effetto negativo è che una richiesta molto lunga blocca anche un processo helper per questo periodo.
Attenzione: Il comando cmk -II della CLI corrisponde alla 'Tabula rasa' della GUI. Ciò significa che il suo utilizzo non è del tutto innocuo. È quindi necessario specificare sempre l'HOSTNAME concreto con questo comando, altrimenti verrà eseguita una tabula rasa sull'intero sito! (cmk -IIvv switch1.checkmk.com e non cmk -IIvv).
Tenete inoltre presente che i comandi si riferiscono sempre e solo al sito locale responsabile di un monitoraggio distribuito. È quindi necessario eseguire il comando sul sito in cui si sta monitorando l'host.
Nozioni di base per il debug: SNMP inline contro net-snmp
Checkmk utilizza SNMP inline dalla versione 1.4. Ciò significa che per impostazione predefinita non utilizziamo più gli strumenti a riga di comando del pacchetto net-snmp, ma eseguiamo la query SNMP utilizzando un modulo Python. Questo ha il vantaggio fondamentale di non dover più avviare e arrestare un processo net-snmp separato per ogni interrogazione OID. A seconda del numero di dispositivi SNMP monitorati, l'uso di SNMP inline riduce il carico della CPU di oltre il 50%.
Attualmente, SNMP inline è l'impostazione standard nella stragrande maggioranza dei casi e funziona in modo affidabile con la maggioranza assoluta degli host monitorati. Tuttavia, sono noti singoli casi in cui è stato necessario disattivare SNMP inline per un singolo host, ma questo aspetto verrà approfondito in seguito.
Nel contesto di questo articolo, disabiliteremo l'SNMP inline per un altro motivo, ossia per scopi diagnostici, e solo temporaneamente per l'host in analisi:
Con l'SNMP inline disattivato, quando si utilizzano i comandi cmk-Ivv/IIvv/nvv, è possibile vedere il comando net-snmp corrispondente e utilizzarlo per ulteriori azioni tramite il copia e incolla.
Ad esempio, con un comando cmk-Ivv HOSTNAME si ottiene il seguente risultato

e può essere utilizzato per copiare il comando ‘snmpbulkwalk -Cr10 -v2c -t 1 -c public -m "" -M "" -Cc -OQ -OU -On -Ot 192.168.1.5 .1.3.6.1.2.1.2.2.1.1’, ad esempio, e modificarlo per ulteriori analisi, se necessario.
È possibile accedere alla regola SNMP inline tramite: WATO ➳ Host & Service Parameters ➳ Access to agents ➳ Hosts not using inline SNMP.

In Checkmk 2.0, è possibile trovare la regola richiesta cercando 'Backend' nel menu Setup . In Regole SNMP è possibile creare la regola Hosts using a specific SNMP Backend (solo Enterprise Edition). Nella regola, si deve aggiungere l'host alla voce Host espliciti e selezionare Usa backend classico alla voce Scegli backend SNMP.

Richieste bulk: Questione di scala
Nel nostro primo articolo sul monitoraggio della rete con SNMP abbiamo visto che SNMPv2c e SNMPv3 offrono un vantaggio significativo rispetto alla versione 1: oltre a poter interrogare i singoli OID tramite snmpget, permettono anche di richiedere interi intervalli di OID in un’unica operazione, utilizzando snmpbulkget o snmpbulkwalk. In Checkmk 1.0, la dimensione dei blocchi (bulk size) degli OID è predefinita, e questo rappresenta un importante vantaggio in termini di prestazioni: invece di inviare dieci richieste separate al dispositivo, il sistema di monitoraggio ne invia una sola. Questo approccio riduce sensibilmente il carico, sia sul dispositivo monitorato che sul server di monitoraggio.
Può sempre accadere che alcuni dispositivi abbiano problemi con la dimensione predefinita di 10 del bulk size e che lo stack SNMP del dispositivo si blocchi a un certo punto quando si esegue una query con una dimensione del bulk superiore, ad esempio, a 8. Di conseguenza, la query sarà incompleta e i servizi non potranno più essere scoperti o interrogati.
Tuttavia, può anche accadere che il tempo totale di esecuzione di una query SNMP sia molto lungo e che, ad esempio, l'interrogazione di uno switch di grandi dimensioni si avvicini al timeout standard di 60 secondi o addirittura lo superi. In questo caso può essere utile aumentare la dimensione del bulk in modo significativo, ad esempio a 60, ma l'aumento della dimensione del bulk, sebbene sia più efficiente, può in realtà avere l'effetto opposto e aumentare il tempo di esecuzione totale. Come si può notare, ci si muove in un campo minato. A proposito di campi minati, abbiamo già sperimentato che un core switch si blocca completamente e si riavvia quando la dimensione del bulk è troppo grande!
Importante: Non possiamo suggerire una dimensione generale del bulk che sia ottimale per ogni caso. Come spesso accade, dipende dal dispositivo in questione. Per questo motivo è necessario "smanettare" un po'. In altre parole, bisogna giocare con i valori fino a quando il problema non si presenta più e in modo che, idealmente, la query non aumenti il tempo di esecuzione totale.
Quindi, per avvicinarsi al problema, si passa alla riga di comando, come descritto nella sezione Fondamenti di debug: il comando cmk. Prima di tutto, dovete guardare a ciò che viene trovato usando cmk -IIv HOSTNAME:
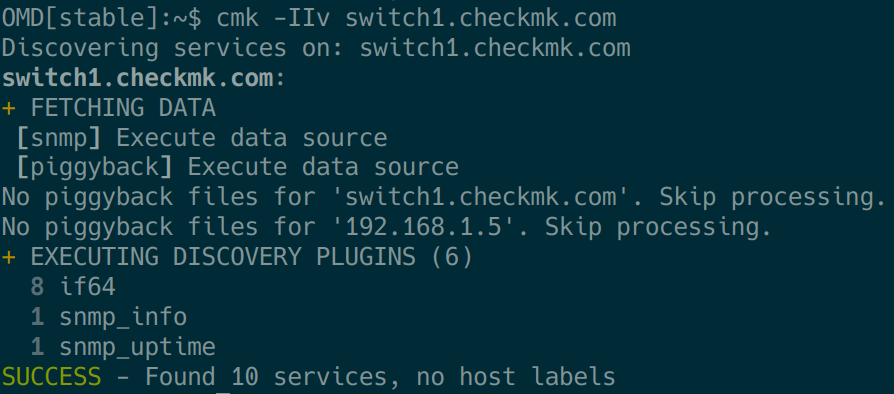
Se in questo caso si verificano errori, con una seconda 'v' si può passare con il comando cmk -IIvv a una modalità ancora più loquace e, come si può vedere nel video qui sopra, rilevare gli OID lenti o che non appaiono.
Una possibile ragione può essere la dimensione del bulk, come già detto. Quindi, se abbiamo identificato un intervallo e disabilitato SNMP inline, come spiegato nella sezione Fondamenti di debug: SNMP inline vs. net-snmp è possibile analizzare specificamente l'OID o l'intervallo di OID interessato e manipolare il bulk size (-Cr10) con valori più piccoli o più grandi fino a trovare il valore ideale. Per una dimensione di bulk di -Cr24, ad esempio, il risultato è il seguente:

Una volta elaborata una combinazione di parametri funzionante, è necessario memorizzarla nelle regole WATO. Per questo abbiamo bisogno della regola Bulk walk: Numero di OID per bulk in Parametri host e servizi ➳ Accesso agli agenti. Qui è possibile regolare la dimensione del bulk:

Anche in questo caso: se si crea questa regola, essa deve essere applicata solo agli host interessati. Non applicatela mai all'intero monitoraggio!
Dopo aver creato questa regola e attivato la configurazione, occorre verificare nuovamente con i comandi cmk corrispondenti se le modifiche apportate portino ora al risultato desiderato, ovvero se i servizi mancanti possono essere interrogati.
Il tempismo è tutto
A parte questo, capita regolarmente che un intero stack SNMP reagisca molto lentamente, oppure che reagiscano solo singole aree OID. Ad esempio, i sensori di temperatura degli SFP Cisco, che possono essere interrogati con il controllo cisco_temperature.dom, sono noti per questo problema. A volte l'interrogazione di questi OID richiede molto più di un secondo per OID (a seconda del dispositivo, anche fino a sette secondi). Per impostazione predefinita, tuttavia, Checkmk è impostato per avere un timeout per OID di un secondo con SNMP inline abilitato o anche disabilitato. Tra l'altro, un timeout di un secondo con cinque tentativi è anche l'impostazione predefinita del pacchetto net-snmp.
Il risultato è che questi OID lenti aumentano significativamente il tempo totale di interrogazione SNMP: 1(s) * 5(tentativi) * x sensori.
Ad esempio, con 120 sensori e un bulk size di 10, abbiamo già un tempo di esecuzione totale di circa 60(!) secondi, senza nemmeno riuscire a scoprire i sensori di temperatura, poiché siamo incappati in un timeout. In questo esempio raggiungiamo anche il timeout predefinito del servizio Check_MK stesso, quindi ci imbattiamo in un timeout generale. Il risultato è che non possiamo più "scoprire" nulla, oppure che i servizi che sono già stati scoperti diventano "stantii" (questo è un esempio molto teorico, in pratica è possibile una complessità molto maggiore).
A questo punto è possibile utilizzare i comandi snmpbulkwalk e impostare i valori di timeout con l'opzione timeout (-t). Ciò consente di creare la regola Impostazioni di temporizzazione per l'accesso SNMP con i valori appropriati in WATO ➳ Host & Service Parameters ➳ Access to Agents.
Tuttavia, è necessario tenere a mente i seguenti aspetti:
- I valori si applicano per OID o per intervallo di OID nel caso di
snmpbulkget. - Il problema viene moltiplicato per: x secondi di timeout * numero di OID interessati * tentativi impostati.
- In che modo le impostazioni di cui sopra influiscono sul tempo di esecuzione totale?
- È possibile che si raggiunga il timeout totale?
- L'istanza di monitoraggio può ancora controllare ogni minuto? Nota: Check_MK/Check_MK Discovery Timeout ≤ Intervallo di controllo
- Quanti helper di Checkmk devo bloccare con questa soluzione? Ogni dispositivo interessato blocca un helper durante un controllo lento.
Considerando tutti questi aspetti, a volte è forse più sensato fare a meno di questi OID o controlli lenti?
Andiamo con calma...
È possibile ottenere le impostazioni di temporizzazione richieste modificando il parametro -t del comando di esempio precedente e impostandolo a sette (-t 7) secondi:
’snmpbulkwalk -Cr10 -v2c -t 7 -c public -m "" -M "" -Cc -OQ -OU -On -Ot 192.168.1.5 .1.3.6.1.2.1.2.2.1.1’
Se in questo modo avete determinato un valore di timeout che consenta di leggere in modo affidabile i sensori di temperatura SFP di cui sopra, aggiungete un secondo in più per sicurezza. Le impostazioni di temporizzazione per la regola di accesso SNMP necessarie a questo scopo possono essere configurate tramite WATO ➳ Host & Service Parameters ➳ Access to Agents.

Importante, ancora una volta: Questa regola può essere applicata solo agli host interessati e mai all'intero monitoraggio! Può capitare che alcune implementazioni SNMP non segnalino 'NO SUCH OID' alla fine di un ramo OID, ma semplicemente non rispondano affatto. Questa è una chiara violazione del protocollo da parte del produttore e, in combinazione con i lunghi timeout, fa sì che queste interrogazioni impieghino improvvisamente secoli e portino inutilmente a timeout totali. In altre parole: Aspettiamo troppo a lungo che arrivi qualcosa senza la consapevolezza che in realtà non arriverà nulla.
Lo stesso principio si applica al retry rate. È improbabile che per nove volte non ci sia risposta, ma che alla decima richiesta venga data improvvisamente una risposta. Pertanto, si dovrebbe scegliere un numero ridotto di tentativi e limitare il numero di tentativi a due o tre, ad esempio. Meglio una fine rapida con un timeout che un timeout senza fine...
... ancora più lentamente...
Se siamo riusciti a rendere le informazioni interrogabili con le impostazioni di cui sopra - ottimo! Diventa però problematico se ci avviciniamo o addirittura superiamo il timeout totale di 60 secondi. In questo caso dobbiamo regolare il timeout totale per i servizi interessati. Per farlo, si può utilizzare la seguente regola: WATO ➳ Host & Service Parameters ➳ Monitoring Configuration ➳ Service check timeout (Microcore).
Infine, procediamo aumentando il timeout di controllo del servizio e limitando questa regola, impostando la condizione Servizi su Check_MK$ e Check_MK Discovery$.

Come già detto, è necessario impostare l'intervallo di controllo in modo appropriato, circa due minuti (timeout ≤ intervallo). Altrimenti i servizi saranno "stantii", perché potranno essere controllati solo più tardi di quanto previsto dalla configurazione. Andiamo quindi in WATO ➳ Host & Service Parameters ➳ Monitoring Configuration ➳ Normal check interval for service checks.
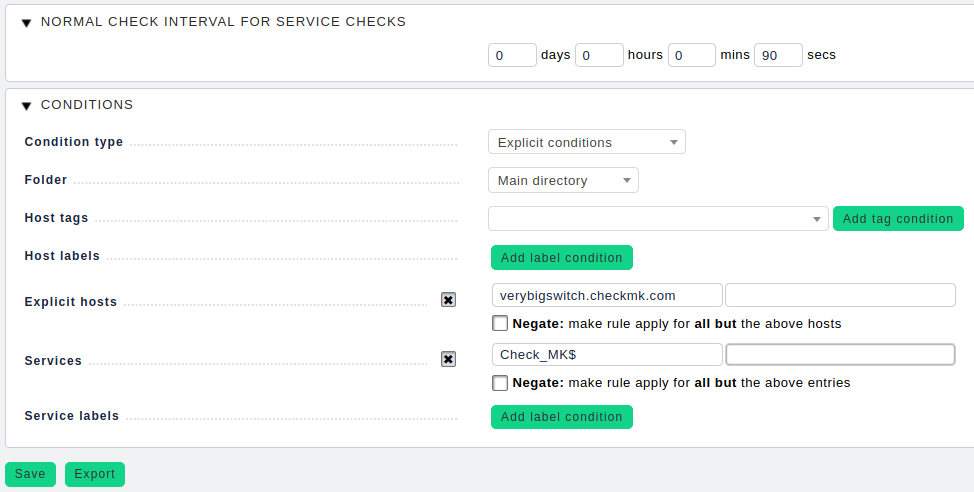
È importante che questa regola si applichi solo al servizio Check_MK e non a Check_MK Discovery o Check_MK HW/SW Inventory. Questi ultimi hanno un intervallo di controllo standard di due o 24 ore, rispettivamente, e genererebbero un carico considerevole se venissero eseguiti con un intervallo di due minuti. Pertanto, è necessario utilizzare l'espressione Check_MK$ nella condizione Servizi.
Importante: '$' è l'espressione regolare (Regexp) per la fine di una stringa. Ciò significa che il modello di ricerca corrisponde solo a Check_MK. Questo assicura che la regola non venga applicata a Check_MK-Discovery o Check_MK HW/SW Inventory, come avverrebbe con il modello di ricerca Check_MK (senza '$' - Infix Search).
Anche in questo caso è importante: Quando si creano queste regole, ricordare di applicarle solo all'host o agli host interessati. Non applicatele mai al monitoraggio complessivo!
... oh, ora è troppo lento!
Ma se si giunge alla conclusione che si preferisce eseguire il polling dello switch più spesso di ogni due, o anche solo ogni dieci minuti, e che i sensori di temperatura lenti sembrano piuttosto inutili, si può disattivare il controllo corrispondente. A volte questa è la scelta migliore. La regola necessaria è riportata di seguito: WATO ➳ Host & Service Parameters ➳ Monitoring Configuration ➳ Disabled checks.

Sapete già che il sottoscritto non ama ripetersi, ma è necessario farlo: Quando si creano queste regole, esse devono essere applicate solo all'host o agli host in questione. Non applicatele mai al monitoraggio complessivo! Unica eccezione: Non volete vedere i servizi su nessuno dei vostri dispositivi, anche se in casi eccezionali potrebbero rispondere velocemente.
A questo punto, sottolineamo brevemente che la disattivazione di singoli servizi tramite una regola del tipo "Servizi disabilitati" non è un'alternativa efficace per questo caso d'uso. Finché viene interrogato un solo sensore, viene eseguito l'intero controllo, anche a causa della dimensione della massa.
Disattivare SNMP inline come soluzione
Infine, in alcuni casi può essere necessario disattivare l’SNMP inline per determinati host. Ad esempio, ci è capitato un dispositivo che, in modo stoico e costante, compilava il numero di sequenza SNMP con un valore fisso di 1, invece di incrementarlo a ogni risposta, come previsto. Si trattava di una chiara violazione delle specifiche RFC, motivo per cui il modulo SNMP di Python rifiutava sistematicamente quei pacchetti. Tuttavia, gli strumenti a riga di comando del pacchetto net-snmp non avevano problemi a interpretarli, il che ci ha permesso di aiutare il cliente applicando una regola personalizzata solo per quell’host - come probabilmente avrai già intuito.
Una soluzione più sostenibile, ma sicuramente meno divertente, sarebbe stata aprire un ticket al produttore dell’hardware.
Conclusione
Come abbiamo visto, la "S" di SNMP sta per "semplice", ma questa semplicità è reale solo quando il produttore implementa correttamente e in modo pulito tutte le RFC. In caso contrario, il sistema può rapidamente trasformarsi in qualcosa di complesso e poco prevedibile, con numerose impostazioni - talvolta interconnesse o addirittura controproducenti. E va detto che, in questo articolo, non abbiamo nemmeno affrontato argomenti come i contesti SNMPv3 o altri aspetti simili.
Nonostante ciò, speriamo che questa panoramica dedicata alla risoluzione dei problemi vi sia stata utile per individuare ed eliminare eventuali criticità SNMP nel vostro ambiente di monitoraggio.
Nella prossima e ultima parte della nostra serie Monitoraggio della rete con SNMP daremo uno sguardo agli sviluppi futuri del monitoraggio SNMP e discuteremo dei possibili successori. Oppure SNMP continuerà a servirci ancora per i prossimi trent’anni?